1. 기존 연구의 문제점
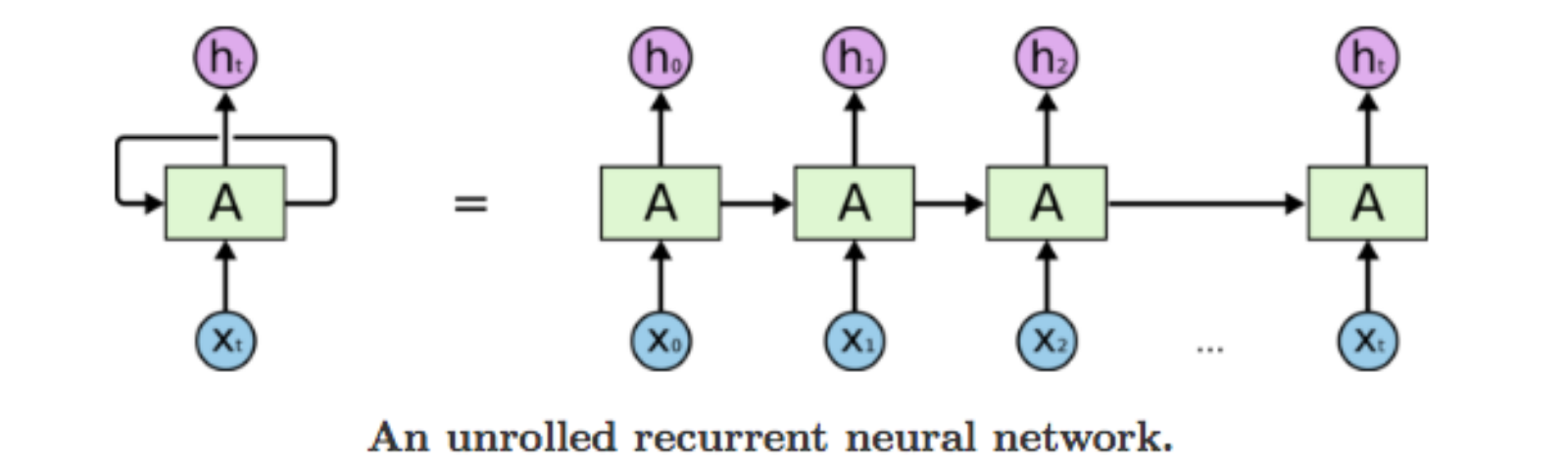
- RNN, LSTM, GRU 기반의 모델들이 NLP분야에서 좋은 성능을 보여주고 있음
- 위의 모델들은 순차적인 계산/처리를 하는데 이는 데이터 특성에 따라 좋을 수도 있고 좋지 않을 수도 있음
- 예를 들어 이미지 형태의 글자 '나는 빨갛고 동그란 사과를 좋아한다'를 한글로 뽑아내는 OCR 어플리케이션은 순차적인 계산/처리가 효과적이지만 이를 영어로 번역하는 경우 'I like red and round apple'로 순서가 뒤바뀌게 Output이 만들어져야한다. 이로 인해 모델이 symbol을 만들 때 헷갈릴 수 있고 효과적으로 feature를 디자인하기 힘들 수 있다.
- 또한 Long term dependency problem으로 인해 Input사이의 길이가 길어질수록 점점 중요도를 반영하기 힘들어지는데 (Back-propagation과정에서 Gradient가 계속 곱해지고 작아짐으로) Task가 복잡하고 Input의 길이가 길수록 위의 문제가 심각해질 수 있다.
2. 본 논문의 Contribution

- 위의 문제를 해결하고자 Attention mechanism 기반의 Transformer 모델을 제안함.
- Transformer는 RNN이나 Convolution 없이 오직 Self-attention기반의 모델
3. 위 모델에서 Positional encoding을 넣는 이유
- transformer 모델은 LSTM, RNN 기반의 모델과 달리 '시간적 연속성'을 모델에서 반영이 안되어 있음
- 하지만 언어의 순서 정보는 언어를 이해하는 데 중요한 역할을 하기에 순서 정보를 넣어주는 처리가 필요하기 때문
4. Transformer architecture
- Encoder Input : (x1,x2,,,,,xn), Encoder Output : (z1,z2,,,zm)
- Decoder Input : (z1,z2,,,zm), Decoder Output : (y1,y2,,,yk)

<Encoder - Decoder> 구조는 동일하지만 위 논문을 잘 이해하기 위해서는 Encoder Decoder의 목적이 뭔지 이해하는 것이 도움이됨.

- 우선 Encoder는 "I love a cat" 의 Input이 들어왔는 때 "I"에 대한 정보를 담고 있는 z1은 "I" 정보뿐만 아니라(물론 attention을 통해 "I"정보가 가장 강하게 내포되긴함) 도움이 되는 다른 단어들의 연관성을 반영하여 FEATURE 정보까지 담게 됩니다.
- Encoder에서 cnn이나 rnn구조가 없는데 무엇을 학습하지? 임베딩된 INPUT VECTOR는 W_K,W_V,W_Q 세가지 Weight를 학습함.
- Decoder의 목적은 Encoder output인 z feature를 활용하여 가장 높은 학률로 매칭되는 단어들을 Output하는 것.
5. 본 논문의 응용에 대한 고찰
- Input과 Output의 순서 의존성이 약한 sequence modeling 혹은 *transduction modeling에 적합할 것
* 고전 기계학습에서 사용하는 transductive learning과 언어학/시퀀스에서의 transduction은 사뭇 다른 의미를 내포하고 있음. 고전 기계학습에서의 transductive learning은 semi-supervised learning과 유사하며 언어학/시쿼스에서의 transduction model은 번역/변환의 의미가 강함.
참고하면 좋을 홈페이지 : dos-tacos.github.io/translation/transductive-learning/ - <시퀀스 예측에서의 transduction> 참고
'Paper review' 카테고리의 다른 글
| EDRN(Enhanced Deep Residual Networks for Single Image Super-Resolution) 리뷰 (0) | 2021.04.12 |
|---|---|
| Character Region Awareness for Text Detection/논문리뷰/paper review (0) | 2021.01.19 |

