BERT
Pre-training of Deep Bidirectional Transformers for Language Understanding
-Bi-directional Transformer로 이루어진 모델
-Pre-trained BERT + classification layer ==> 다양한 NLP task 수행

- Input --> embedding layer + transformer layer -> Contextual represenation of token --> Classification layer
- Wordpiece tokenizing을 통해 입력 문장을 token sequence를 만들어 학습에 활용
1. Wordpiece tokenizing
- byte pair encoding
1.1 띄어쓰기 기반 단어 나누기
1.2 character 기반 한 글자씩 나누기
ex) 나, 는, 사, 과, 야
1.3 맨 앞글자를 제외한 나머지 글자는 ##붙이기
ex) 나는 사과야 ==> 나, ##는, ##사, ##과, ##야
1.4 중복을 제거한 vocal 후보 만들기
ex) 나는 사과야, 나는 배야 ==> 나, ##는, ##사, ##과, ##야, ##배
1.5 bi-gram pair만들기
ex) 나, ##는, ##사, ##과, ##야 ==> (나,##는), (##는,##사),(##사,##과)....등등
1.6 가장 많이 나온 빈도의 pair를 best pair로 지정
1.7 best pair는 합치기
ex) (##사,##과) ==> ##사과
2. Pre-training
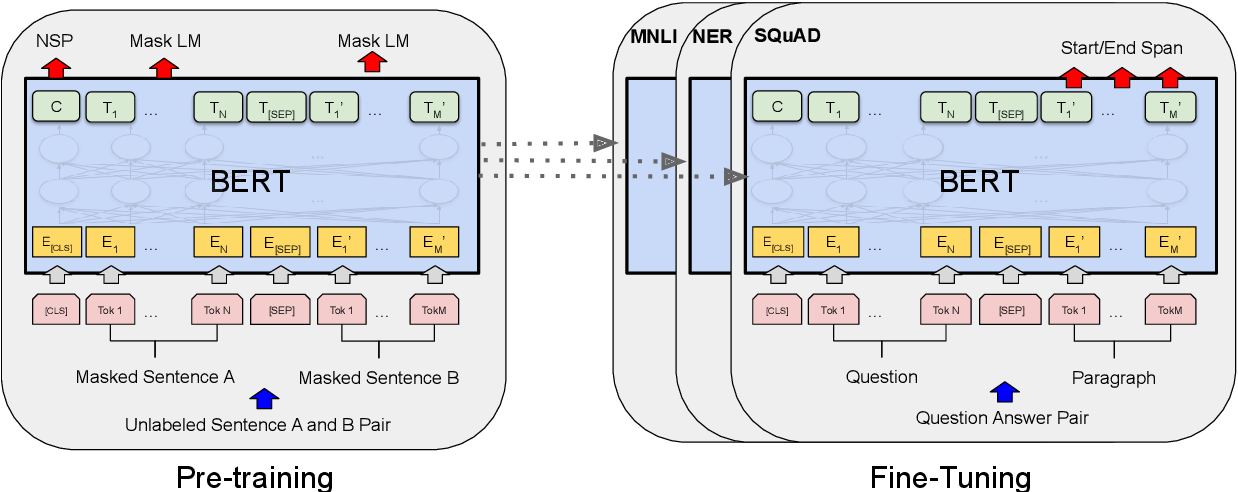
2.1 MLM (Masked LM)
3 Types : Masking, random changing, unchanging
- Masking : 나, ##는, ##사과, ##야 ==> 나, Masking, ##사과, ##야
- Random changing : 나, ##는, ##사과, ##야 ==> 나, ##가, ##사과, ##야
- Unchaning : 나, ##는, ##사과, ##야 ==> 나, ##는, ##사과, ##야
2.2 Embedding
3 Types: Token Embedding, Segment Embedding, Position embeddings
-Token Embedding : 일반적인 word embedding
-Segment Embedding : Sentence가 2가지가 들어가는 각 Token이 어떤 sentence에 해당하는지에 대한 Token
-Position embeddings : INPUT TOKEN들이 시계열로 들어가는 것이 아니라 병렬로 들어가기 때문에 position에 대한 정보를 줘야함
2.3 Next sentence prediction(NSP)
- 두 가지 sentence가 입력으로 들어갔을 때, 위 두 문장의 관계도를 통해 Next sentence인지 아닌지를 판별하는 binary classifier
2.4 Application with Pre-trained BERT

- Sentence pair classification
- Single sentence pair classification
- Question and answering
- Single sentence tagging
BERT 이후 논문 소개
RoBERTa
A Robustly Optimized BERT Pretraining Approach
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Language model pretraining has led to significant performance gains but careful comparison between different approaches is challenging. Training is computationally expensive, often done on private datasets of different sizes, and, as we will show, hyperpar
arxiv.org
논문의 main 컨셉
- BERT가 나온 후 BERT 기반으로 다양한 네트워크들이 나옴
- 하지만 기존 BERT를 활용 + Training data 증대 /하이퍼 파라미터 조정/ Batch size 늘림 으로도 충분히 성능이 높아질 수 있음을 주장
- 또한, 기존 BERT에서 Pre-trained할 때 활용하는 대표적인 기술 1) masking 2) Next sentence classification 중에서 2)의 효과에 대한 의문을 제기 + 실험을 통해 확인함
- 하지만 masking의 경우 뚜렷한 효과가 있으며 기존 BERT는 3가지 TYPE으로만 마스킹을 진행하고 있으나 현 논문에서는 10가지 타입의 다양한 Masking을 도입함으로써 성능 증가를 보여줌
- 기존 BERT에서 단순히 Training data를 늘리고 batch size를 늘림으로써도 성능이 더 올라갈 수 있음을 보여줌