PP-OCR: A Practical Ultra Lightweight OCR system 논문 리뷰
PP-OCR (A Practical Ultra Lightweight OCR system)
PPOCR은 최근 바이두에서 출시한 OCR 경량 시스템이다.

위 논문에서는 OCR이 낮은 Computing power에서 적용이 되야하는 실제 사례가 많음을 강조하고,
이에 모델의 성능과 모델 사이즈(Computing power,speed...)의 Trade off 에 관해 많은 고찰과 실험을 진행하였다.
물론 실험의 최종 목표는 모델의 성능을 높히면서도 모델을 경량화하기 위함으로,
여러가지 Strategies를 도입하고 Ablation study을 통해 그 유효성을 검증한다.
PPOCR system은 크게 3가지 파트 (Text Detection, Detected box rectification, Text Recognition)로 구성되어 있다.
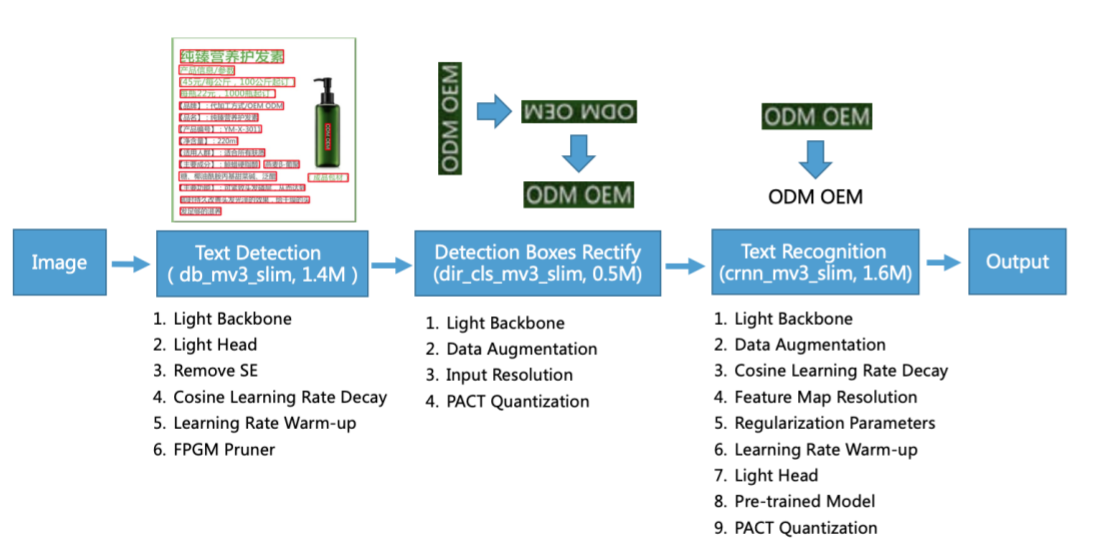
1. Text Detection

글자 영역의 위치를 bbox 형태로 찾아내는 역할을 담당한다.
PPOCR은 Baseline network으로 Differentiable Binarization(DB)를 활용하고 있다.
*DB는 Segmentation 기반의 Network
PPOCR은 DB에 간단한 Post-procesing을 적용하여 더욱 효과적으로 만들며 6가지 추가적인 Strategy를 적용하며 경량화
된 Text detection을 만들었다.
6가지 Strategy란, 1.1 Light backbone, 1.2 Light Head, 1.3 Remove SE module, 1.4 Cosine Learning rate decay, 1.5 Learning rate warm-up, 1.6 FPGM pruner 이다.
1.1 Light backbone
Backbone 사이즈는 전체 Text detection 모듈에 가장 dominant한 영향을 준다.
그래서 애초에 고를때부터 경량화된 모델을 실험후보군(MobileNetV1,MobileNetV2,MobileNetV3,ShuffleNetV2)으로 가져왔고,
"MobileNetv3-large-x0.5"가 가장 최적의 모델로 선정되었다.

이 실험의 디커중에 한 네트워크 중에서도 Scale에 따라 성능차이가 꽤 난다는 결과도 나와있다.
1.2 Light Head
Text detector의 Head는 object detection에서 많이 활용되는 FPN 구조와 유사하다.
이와 같은 head/FPN를 쓰는 이유는 다른 Scale의 Feature maps들을 decov + fuse 시켜서 작은 region text들까지 잘 잡아내기 위함이다.
이 과정에서 'Light' 라는 단어가 붙은 이유는, 1x1 conv filter를 활용하고 있기 때문이다.
1x1 filter를 왜 쓰지? 라고 생각할텐데,.. 보통 새로운 feature를 잡아내기 보다는 size는 변함없이 가되, inner channel 숫자를 바꿔주고 싶을 때 1x1 con filter를 쓴다.
이 논문에서는 inner channel을 줄여주는 용도로 해당 filter를 사용하고 있고, 이는 model 경량화에 꽤나 도움이 된다.
1.3 Remove SE module

SE module 의 목적은 위의 그림과 같이 feature map이 N개의 Channel 만큼 있다고 할때,
이 중에서도 feature map들마다 중요치가 다르기에 중요도 weight를 한번 더 곱해서 Attention을 주는 것이다.
Resnet, GoogleNet등 여러가지 네트워크에서 적용되었고 특히 Vision Application에서는 성능 향상에 효과적임이 자명하게 증명된 바 있다.
하지만 위 논문에선, 제목 그대로 SE module을 삭제함으로서 model weight를 경량화 시킨다. (MobileNetV3에 SE module이 굉장히 많이 포함되어 있음)
그 이유에 대해서 저자는 이미지 해상도를 언급하는데, 입력 데이터가 고해상도 이미지의 경우 Channel wise feature response가 명확하지 않고 측정되기 어렵다는거다.
그래서 성능 향상에 비해서 Cost efficiency 가 너무 떨어진다는 주장하며 SE module을 모두 제거한다.
1.4 Cosine Learning rate decay

이거는 사실 경량화 보다는 학습속도랑 정확도랑 더 관련된 것 같다.
대부분 알고 있듯, Learning rate는 초반에는 상대적으로 큰 숫자로 두고 학습이 어느 정도 진행되고 나서는 decaying 시켜서 정확도를 높히는데,
이러한 과정을 Learning rate decaying이라고 부른다.
여려가지 방법이 있는데 위 논문에서는 8가지 방법에 대해 적용해보고 Best를 골랐고 그게 Cosine Learning rate decay이다.
1.5 Learning rate warm-up
이도 Learning rate와 연관되어 있는데, 위의 설명에서 더 추가를 하자면.
초기 Learning rate 설정을 할때 상대적으로 큰 것을 채택하는 것은 맞지만 너무 큰 값을 하게 되면. 오히려 학습이 불안적해지고 발산하게 되는 경우가 종종 있다.
그래서 한 논문에서는 Learning rate warm-up이라고 초반에 조금 작게 설정하다가 키우는 방법을 제안하고 Image classification에서는 유효함을 검증했다.
그리고 이 논문에서도 이를 도입해서 Text detection에서도 효과가 있음을 입증한다.
1.6 FPGM pruner

pruning은 경량화의 대표적인 방법 중 하나이다.
Pruning을 할때 가장 핵심은 Performance degradation을 최소화 시키는 것이다. 이 모델에서는 FPGM Pruning 방법을 채택하여 중요도가 떨어지는 sub-network를 찾아 제거한다.
2. Detected box rectification(Direction Classification)
이 모듈에서도 성능하락을 최소화하면서 파라미터를 줄이는 방법에 대해 설명하고 있다.
크게 네가지로, Light Backbone, Data Augmentation, Input Resolution, PACT Quantization이다.
2.1. Light Backbone
Backbone selection과정은 위의 1.1에서와 내용은 동일하다.
다만, Direction classfication은 위의 Text detection보다 상대적으로 Task 자체가 간단하기 때문에, MobileNetV3 중에서도 더 가벼운 모델인 'MobileNetV3_small_x0.35'을 활용한다.
2.2. Data Augmentation
데이터 증강부분은 경량화보다는 성능 향상을 위함으로 실험이 진행되었다.
가장 많이 활용하는 BDA(Base Data Augmentation)를 포함하여 RandAugment, AutoAugment 등등 여러가지 최신 Data augmentation 기술들까지 모두 적용했다.
Data Augmentation은 대부분 성능 향상에 도움이 될 거라고 예상하지만 응용 어플리케이션에 따라 경향성이 다 다르다.
그리고 위 논문에서는 Direction Classification 학습에 도움이 되는 Data Augmentation 기법이 BDA, RandAugment, RandErasing임을 실험으로 증명한다.
2.3. Input Resolution
입력 해상도에 대한 내용이다.
우선 입력 해상도와 성능은 일반적으로 비례관계에 있다고 알고 있다.
하지만, 입력 해상도는 Computational cost와 반비례 관계에 있기에 Task에 따라 최적의 Input resolution을 찾는게 좋다.
이 모듈은 MobileNet 중에서도 가벼운 모델을 활용하기 때문에 입력해상도를 고해상도로 바꿨을 때, 증가하는 Computaional cost가 미미하다.
그래서 기존의 (32x100) 에서 (48x192)로, 고해상도 Input resulution을 활용하고 있다.
2.4. PACT Quantization

Quantization도 모델 경량화 기법 중 하나이다.
여기서 활용하고 PACT는 online quantification 방법으로, 학습 과정에 포함되어 있다.
결국 최대/최소값이 어느 정도의 범위 안에 있다는 것을 가정아래 Clipping을 Activation을 진행한다.
3. Text Recognition

Text Recognition은 Detected box rectification(Direction Classification)을 통해 Align된 Text bbox를 받아서 실제로 무슨 글자인지 인식하는 모듈이다.
Light Backbone, Data Augmentation, Cosine Learning Rate Decay, FeatureMap Resolution, Regularization Parameters, Learning Rate Warm-up, Light Head, Pre-trained Model, PACT Quantization 기법이 활용되었다.
Light Backbone, Cosine Learning Rate Decay, Learning Rate Warm-up, PACT Quantiazation은 내용이 위의 모듈과 유사함으로 생략한다.
3.1 Data Augmentation
위의 설명과 마찬가지로 각 Task에서 효과적인 Data Augmentation은 다 다른데, Text recognition에서는 BDA와 TIA 기법이 효과적임이 검증되었다.

TIA는 다음 그럼과 같이 여러 Point들을 잡아서 다양하게 geometric transformation을 준다.
3.2 FeatureMap Resolution

이 파트에서는 Feature를 down-sampling 할 때 활용하는 Stride parameter를 몇으로 설정할지는 실험한 파트다.
결론적으로는 (1,1)로 FeatureMap의 정보를 최소화하는게 가장 효고가 좋음을 뜻하는것 같다.
3.3 Regularization Parameters
정규화는 모델의 과적합을 방지하고자 활용하는 기법으로 근래에는 굉장히 많은 방법들이 제안되고 있다.
이 논문에서는 L2 decay 를 활용하고 있고 이미 너무 유명하고 기본적인 방법이라 자세한 내용은 생략.
3.4 Light Head
Fully connected Layer에 들어가기전에 Feature는 Flattening 되어 Input으로 활용된다. 이 과정에서 마지막 Flattened Feature의 Dimesion은 Clasification score에 직접적인 영향을 끼친다.
Dimension이 클수록 많은 정보를 담을 것이라 생각하지만 Curse of Dimensionality(차원의 저주)와 같이 꼭 그렇지도 않다.
그래서 모델 디자인 시 최적의 Dimension을 찾는데 이 논문에서는 48 dimension을 실험적으로 검증하여 채택하고 있다.
3.5 Pre-trained Model
위 모델에서도 Transfer learning을 적용하는게 더 효과적임을 보여준다.
4. Experimental Setup & Result
Text detection, Direction Classification, Text recognition 등 이 세 파트에서 위의 설명된 Strategy 들의 유효성을 검증한다. 이 전략을 도입시 성능 증가와 Inference time이 얼마나 줄었는지를 알려주는 내용이 대부분이다.
사실 이 부분에서 어떠한 이유로 성능증가가 있고 Text recognition이라는 응용은 어떤 특징이 있기에 이런 결과가 나오는지에 대한 디스커션이 전혀 없어서 개인적으로 좀 아쉽다. 또, 이 네트워크의 Loss function 구성이나 end-to-end 인지 등 네트워크 소개가 없어서 논문만 봐서는 전체 구조와 학습과정에 눈에 보이지 않는다. 다만 어떠한 모델을 활용할때 경량화 시키기 위해서 어떠한 전략들을 시도하는지 등의 컨셉을 잡기에 좋은 논문인듯하다.